What is llms.txt: The Webmaster’s Guide to New AI Sitemap Standard
As conversation-driven AI engines like ChatGPT Search, Gemini, Claude, and Perplexity redefine how users find information, webmasters face a fundamental challenge: How do we make our websites legible to artificial intelligence? Traditionally, search engine spiders (like Googlebot) read HTML...
 Tekef
Tekef

As conversation-driven AI engines like ChatGPT Search, Gemini, Claude, and Perplexity redefine how users find information, webmasters face a fundamental challenge: How do we make our websites legible to artificial intelligence?
Traditionally, search engine spiders (like Googlebot) read HTML structures and sitemaps to index pages. Today, AI bots (like GPTBot and ClaudeBot) ingest, summarize, and cite web pages in real-time answers.
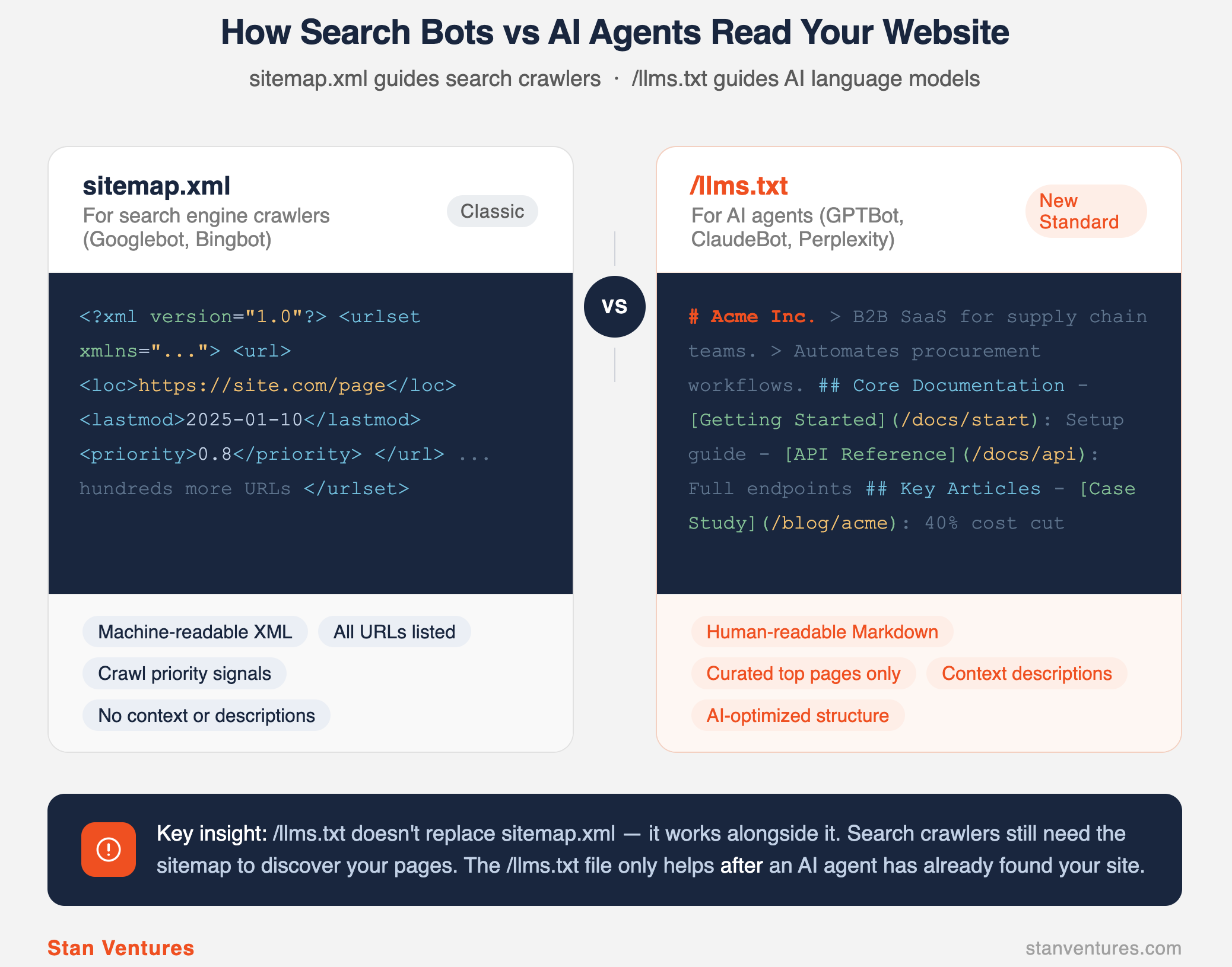
To bridge this gap, a community-driven specification has emerged: the `/llms.txt` standard (documented at llmstxt.org). Placed at the root of a domain, it acts as a sitemap designed specifically for LLMs.
But as AI search emerges, is /llms.txt a genuine breakthrough for visibility, or is it an overhyped engineering distraction?
In this guide, we break down what /llms.txt is, analyze its core mechanics, address critical industry critiques from search authorities, and outline who should—and shouldn’t—implement it.
What is `/llms.txt`?
Similar to how robots.txt specifies files that web crawlers should not touch, /llms.txt is a raw Markdown file that provides a curated, high-signal roadmap of the pages AI agents *should* read.
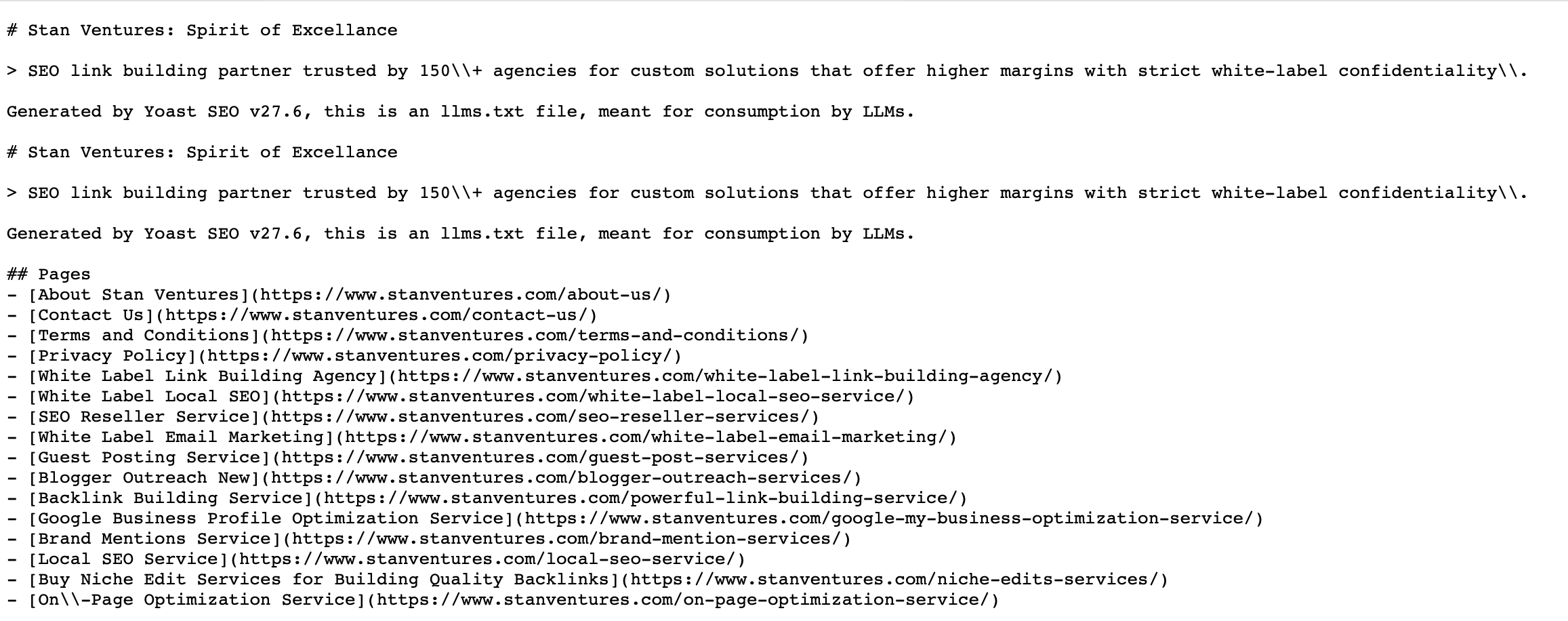
The Standard Format
Placed in the root directory (e.g., yourdomain.com/llms.txt), the file consists of:
H1 Header (Required): The name of the organization or project. Blockquote (Recommended): A concise, high-level summary of what the site does, helping the LLM immediately orient its context. H2 Sections (Categorized Links): A structured, bulleted list of links to your highest-value canonical resources (e.g., core documentation, articles, product pages). Each link is paired with a brief, descriptive summary of its contents. Companion Files (e.g., `/llms-full.txt`): An optional, single comprehensive file containing the full text of your key pages in Markdown, allowing an LLM to ingest your site’s main insights in a single request.A Crucial Reality Check: “Discovery” vs. “Functionality”
A common misconception in the digital marketing space is that creating an /llms.txt file is an SEO ranking factor that will magically elevate a website’s ranking in Google or ChatGPT.

As John Mueller (Search Relations Lead at Google) recently pointed out, it is vital to separate “Discovery” from “Functionality”:
Discovery (SEO): The process of a global search engine finding your website and pages in the first place.
Functionality (UX for Agents): Once an agent or a search engine has already arrived on the page, helping it complete its task with maximum accuracy and minimum overhead.
“You don’t ‘do them’ for SEO (to be found), but if you’re responsible for the website overall, ensuring a high ‘discovery rate’ (SEO) together with a high conversion rate is useful to justify your work.”
— John Mueller
What Not to Expect (The Discovery Reality)
AI answer engines do not browse the raw internet on their own in real time for every query. Instead, when a user asks a question, ChatGPT Search or Perplexity runs a query against a standard search engine index (like Bing’s API) to retrieve the top 10–20 ranking pages.
If your website lacks traditional search authority and does not rank in the top search engine results, the AI crawler will never discover your site, and it will never read your `/llms.txt` file.
/llms.txt does not bypass the need for core SEO foundations; it only enhances what happens after your page is fetched.
What to Expect (The Real Functional Benefits)
If your website already ranks well and is regularly fetched by AI search crawlers, /llms.txt provides substantial functional advantages:
Precision in AI Citations: AI engines synthesize multiple web pages to write a single response. If a bot reads your /llms.txt file, it receives a highly structured, accurate summary of your site’s structure, reducing the chance of the engine misinterpreting your brand or hallucinating facts about your business.
RAG-Pipeline Legibility: Many businesses build internal corporate AI tools and custom assistants. These systems crawl industry resources using RAG (Retrieval-Augmented Generation). Exposing /llms.txt acts as an open invitation for B2B enterprises to seamlessly sync your insights into their custom databases, establishing your brand as a foundational data source.
Server Efficiency: AI crawlers can put significant load on web servers by repeatedly requesting bloated HTML pages. By pointing agents to a centralized directory of light Markdown files, you drastically reduce server bandwidth and processing overhead.
Who Should—and Shouldn’t—Use `/llms.txt`?
Following the rule of “prioritize needs before dreams,” implementing /llms.txt is not a priority for everyone.

Who Should Use It:
Developer Portals & API Providers: AI coding assistants (Cursor, GitHub Copilot) rely heavily on parsing developer docs. Having a clean map is highly valuable for code generation.
Technical B2B & SaaS Brands: Companies that publish detailed guides, research whitepapers, or software benchmarks where the target audience uses AI tools to research buying decisions.
High-Volume Educational Databases: Academic institutions, research libraries, and databases that want their public records to be accurately cited by conversational search systems.
Who Should Skip It (For Now):
Local Brick-and-Mortar Businesses: A local plumber or dentist is discovered via local intent maps and reviews. An /llms.txt file will not drive foot traffic or improve local map rankings.
General B2C E-commerce Sites: Server logs show negligible transactional shopping traffic driven by autonomous agents today. Building custom directories for non-existent agents is a speculative dream.
Sites with Poor Core SEO Foundations: If a site is plagued by slow loading speeds, broken redirect loops, or thin, low-quality content, developer hours are far better spent fixing these foundational discovery elements.
Looking Out to the Future
The /llms.txt file is currently a community-driven initiative, but its underlying logic is sound.
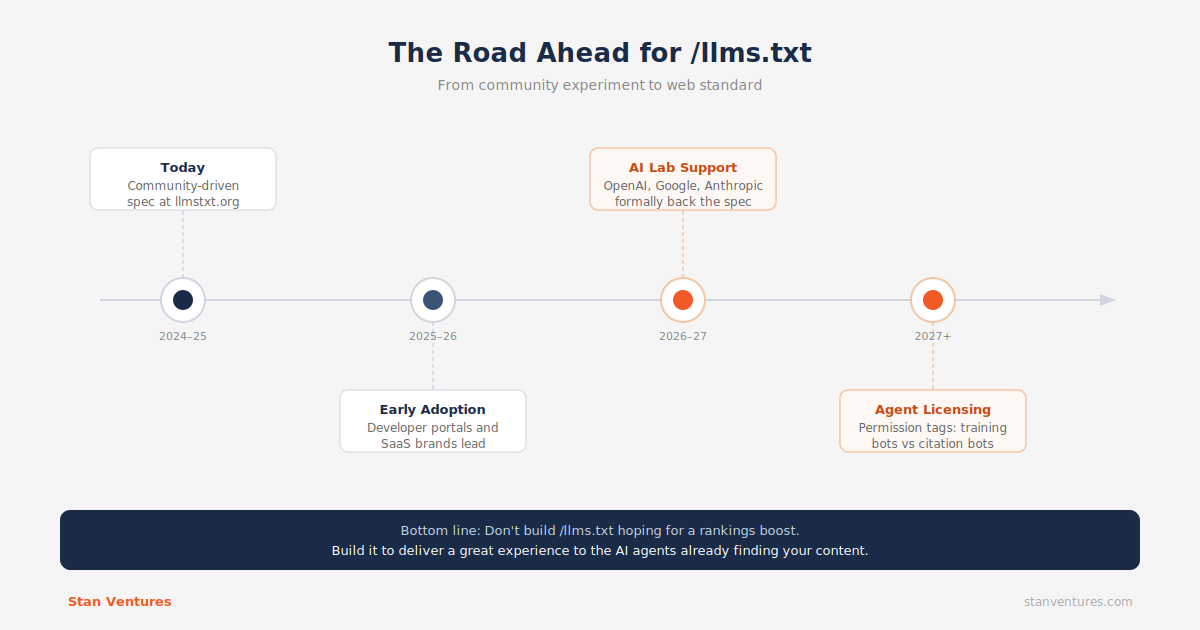
As the web adapts to AI, we can expect:
Formal Standardization: Major AI labs (OpenAI, Google, Anthropic) or standard bodies (like W3C) may eventually codify a universal machine-readable directory standard to save crawling bandwidth.
Agent Licensing Protocols: /llms.txt may evolve to include permission tags that distinguish between search-grounding engines (which drive citation traffic) and model training bots (which scrape data to train models without traffic return), giving webmasters granular control over their intellectual property.
The Bottom Line: Don’t build an /llms.txt directory hoping for a sudden surge in Google rankings. Build it to provide an excellent “user experience” for the AI agents that are already finding their way to your content.

Dileep Thekkethil is the Director of Marketing at Stan Ventures, where he applies over 15 years of SEO and digital marketing expertise to drive growth and authority. A former journalist with six years of experience, he combines strategic storytelling with technical know-how to help brands navigate the shift toward AI-driven search and generative engines. Dileep is a strong advocate for Google’s EEAT standards, regularly sharing real-world use cases and scenarios to demystify complex marketing trends. He is an avid gardener of tropical fruits, a motor enthusiast, and a dedicated caretaker of his pair of cockatiels.








![AI Search & SEO: Key Trends and Insights [Webinar] via @sejournal, @lorenbaker](https://www.searchenginejournal.com/wp-content/uploads/2025/04/conductor_ap_may2025-637.png)