97% of llms.txt Files Never Get Read (137,000 Sites Analyzed)
Using Ahrefs Web Analytics and Bot Analytics, we analyzed the server logs and live traffic of 137K domains, plus the user agents hitting all of them. Here’s what we found. In late May 2026, Google took both sides of...
 Astrong
Astrong

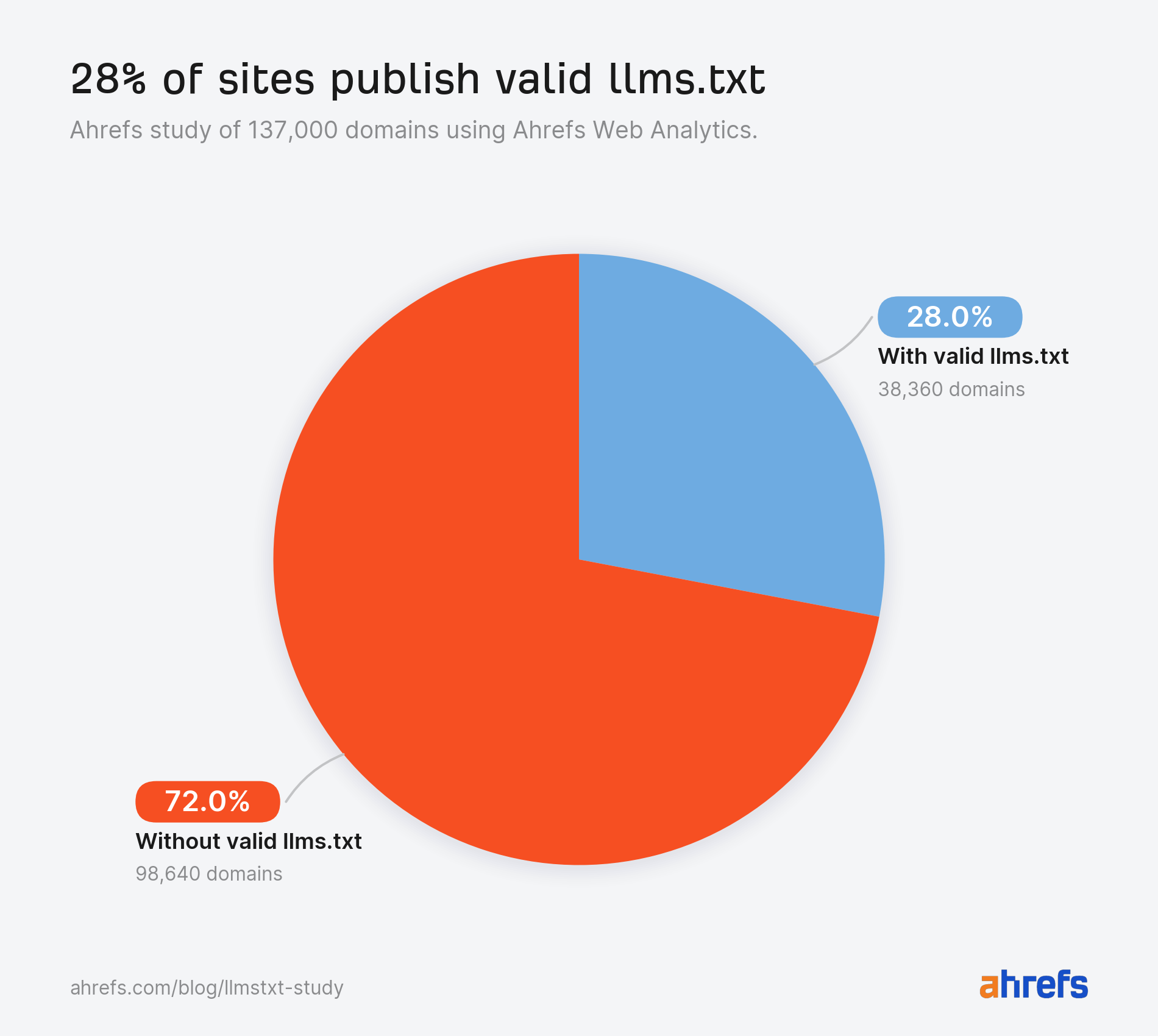
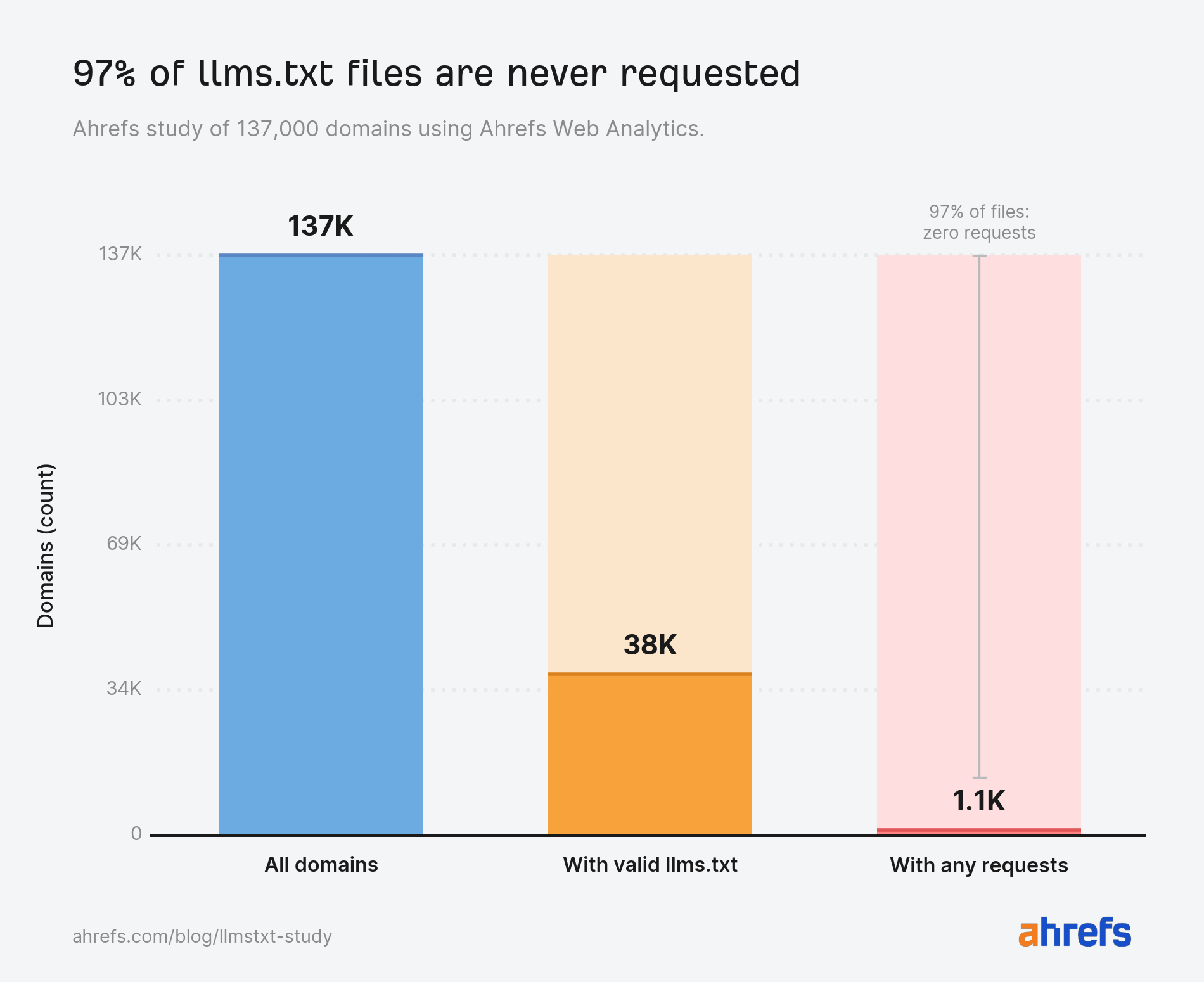
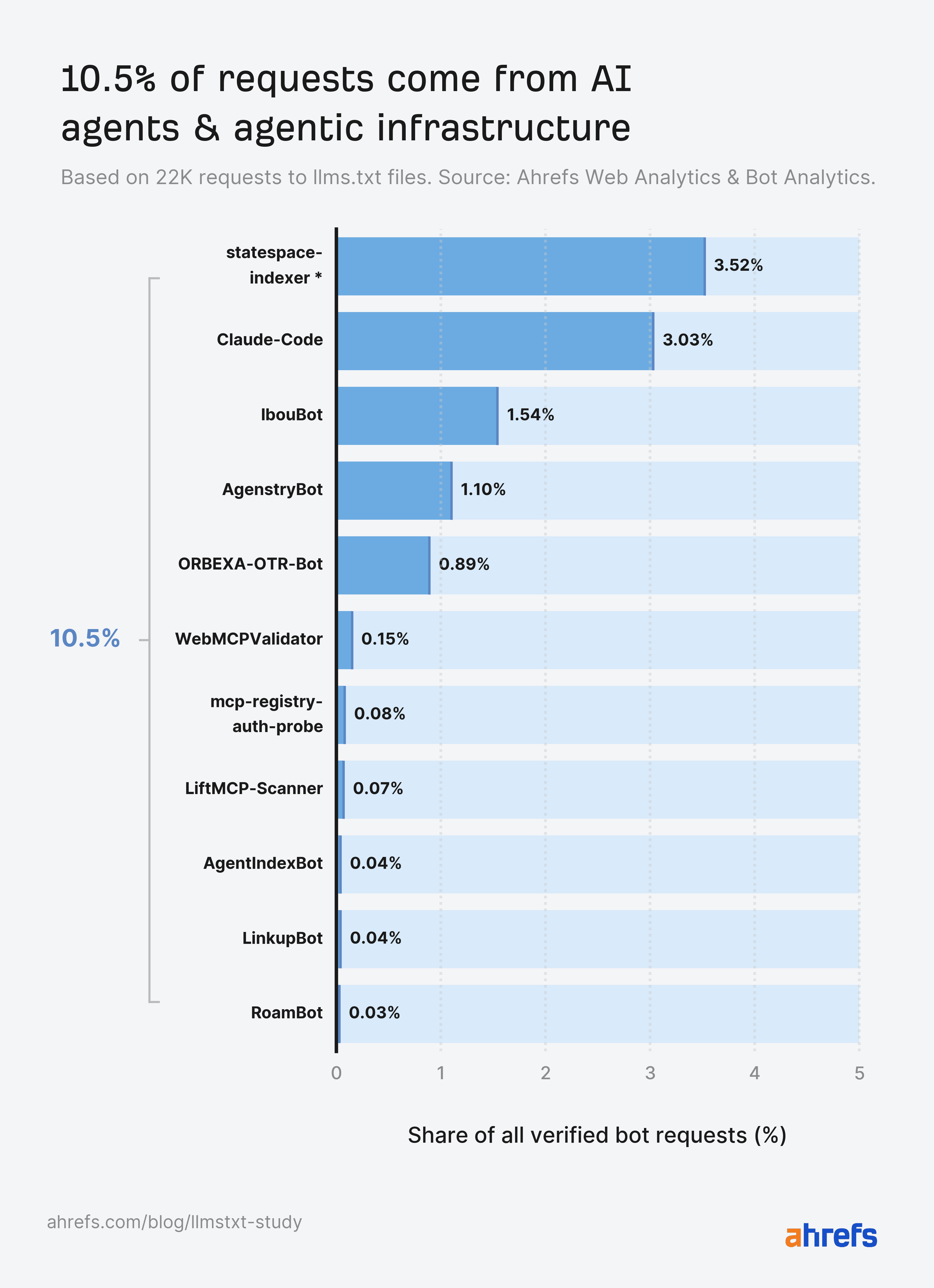
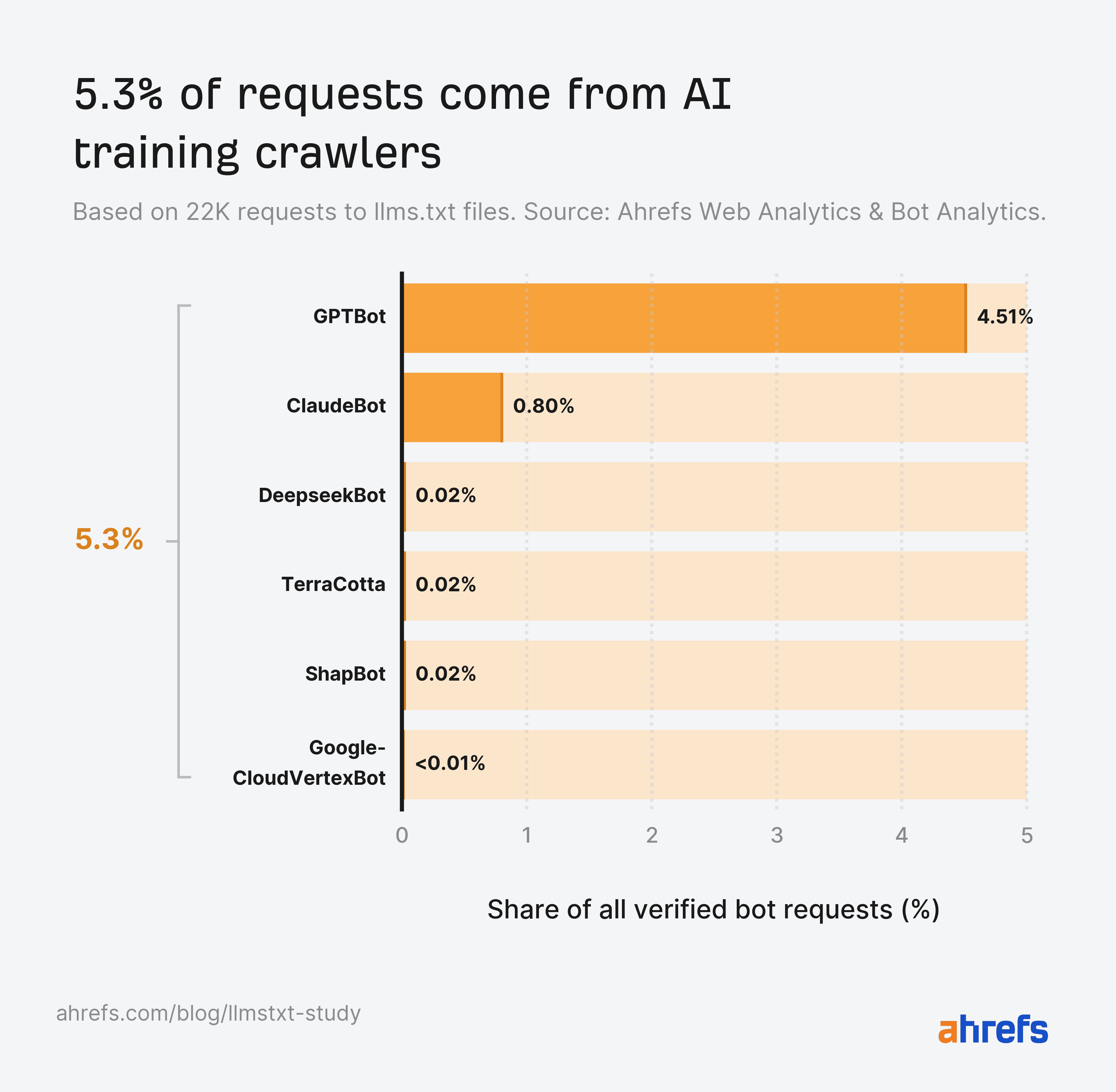
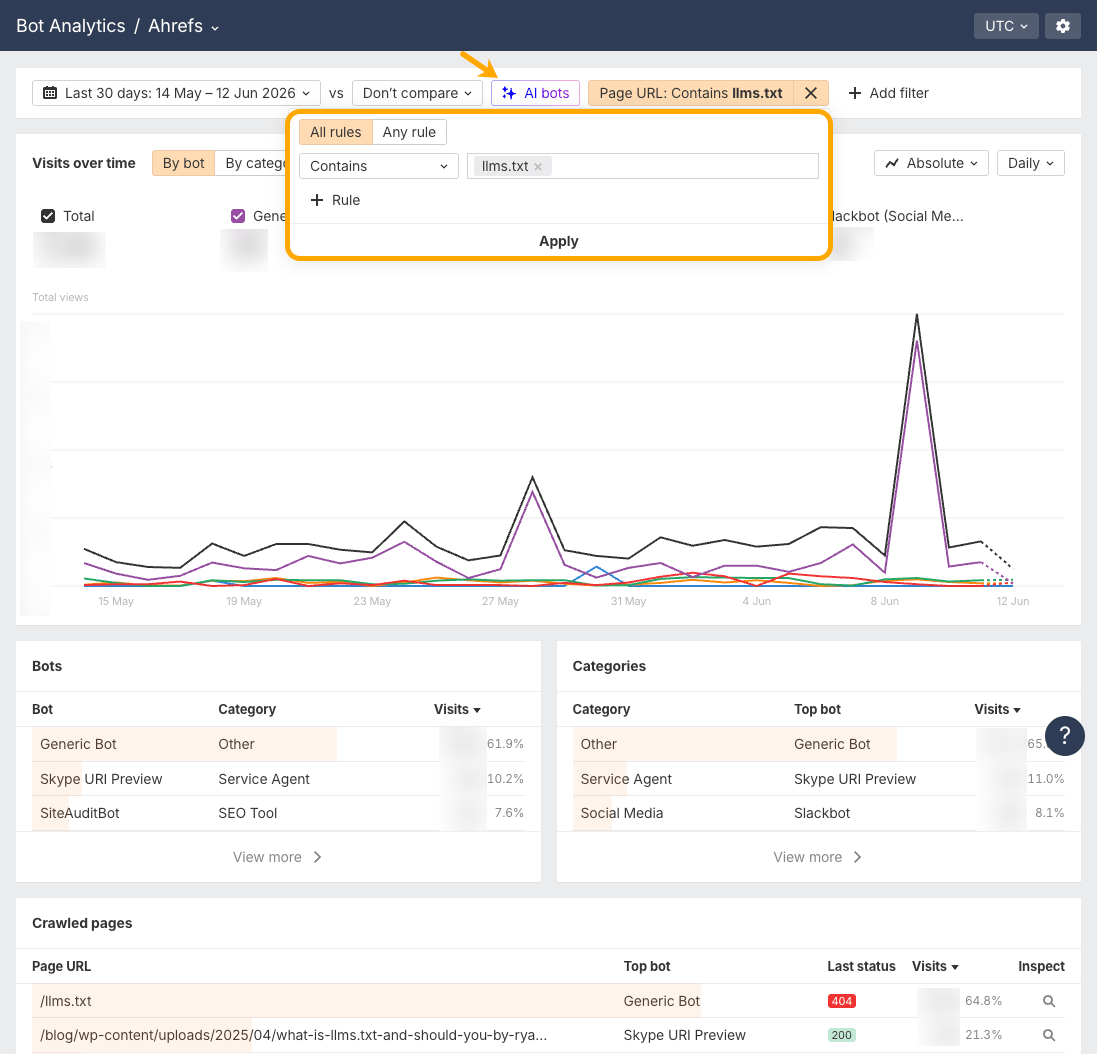
Everyone has an opinion on llms.txt, but when it comes to actual evidence we have only single-site logs or the odd small-scale experiment. Using Ahrefs Web Analytics and Bot Analytics, we analyzed the server logs and live traffic of 137K domains, plus the user agents hitting all of them. Here’s what we found. Top findings In late May 2026, Google took both sides of the llms.txt argument in under a week. Its new guide on optimizing for generative AI features told site owners, in a section literally titled “mythbusting”, that machine-readable files like llms.txt aren’t needed to appear in generative AI search. Days later, the Chrome team shipped an llms.txt check inside Lighthouse’s experimental Agentic Browsing audits, with documentation explaining that without the file, agents may spend more time crawling a site to understand its structure When Lily Ray pressed Google’s John Mueller on the contradiction, he explained that llms.txt is “not done for search.” It’s a “temporary crutch, perhaps to save some tokens” for AI coding tools parsing developer documentation—not something non-developer sites need to worry about. He also stated that site owners who check their logs will find very little AI agent traffic. This is something we decided to test. What llms.txt is (and what it isn’t) Before we go any further, let’s clear up what llms.txt actually is. Llms.txt is a single index file, written in markdown, placed at a site’s root. Proposed by Jeremy Howard, co-founder of Answer.AI and fast.ai, in 2024, it summarizes what a site is and links its most important content. The idea being that LLMs and agents can use this information to orient themselves without crawling everything. The “AI visibility” framing around llms.txt came later on, attached by the SEO industry as adoption spread on the speculation that AI platforms would reward the file. Two things it is often confused with, and isn’t. This study measures the index file, and only the index file. Our study focuses on 137,210 domains in Ahrefs Web Analytics that received traffic in May 2026. We checked each domain root for an llms.txt returning HTTP 200, then used Ahrefs Bot Analytics to examine every request to /llms.txt paths across the population, split by HTTP response (200 vs 404) and classified by channel and individual user agent. To rule out soft 404s and phantom files, we also confirmed each file was actual Markdown rather than HTML, and screened titles and content for error signals like “404” or “Page not found” It’s important to note: Google Search’s guidance says you can skip it, the Chrome team audits for it, and Mueller calls it a stopgap for coding tools. So amid all the mixed messages, how widespread is llms.txt actually? Among the 137K domains in our study, 28% publish these files. More than one in four domains (38,000) in our population have adopted llms.txt, despite the fact that no major AI platform has ever committed to reading it. Adoption has been driven by speculation that AI platforms may start consuming the file, rather than by any confirmation that they do. Almost every llms.txt file in our study is unread. Of the ~38,000 domains with a valid file, 97% saw no requests for it whatsoever in May. No bots. No humans. Nothing. The remaining 3% (1.1K domains) received all of the llms.txt traffic we measured. Our data suggests John Mueller is right. Not only will you find very little AI traffic as a result of this file—you will find very little traffic, period. If you publish an llms.txt file today, the most likely outcome by far is that nothing ever fetches it. The 3% of files that do get read, though, get read by interesting visitors. We’ll focus on them for the rest of the study. Llms.txt files are written for machines, and machines are nearly the only things reading them. Across the files that received traffic, 96% of requests came from bots. Humans accounted for 4%, and a chunk of those appear to be SEOs sharing llms.txt links in chat apps, where unfurl bots dutifully fetch them. Slackbot alone fetched llms.txt files more often than PerplexityBot did. Perplexity is one of the AI search engines llms.txt was seemingly designed to help, so finding that a chat app’s link-preview bot outfetched it speaks volumes about how much real AI search interest these files are actually generating. Many sites publish llms.txt precisely because they think it will improve their chances of appearing in ChatGPT answers, or landing Perplexity citations, or winning an AI Overview. But our data tells a different story: 77% of the bots fetching llms.txt aren’t AI tools at all. To understand which bots were requesting llms.txt, we classified every user agent into twelve categories. Individually, no AI bot category makes the top four. SEO audit tools (21.7%), Other and unidentified (14.9%), General web crawlers (13.1%), and Tech profiling tools (11.6%) all send more requests than any one AI bot. Sidenote. That top category also contains Chrome’s Lighthouse audit, the check that reignited the llms.txt debate. It made just 22 requests—roughly 1 in 1,000. The biggest standalone AI category, AI agents, sits in fifth place at 10.5%. But when you combine the four AI categories (training crawlers, retrieval bots, assistants, and agents), AI bots become the largest single bucket at 19.5%. The bot traffic splits into three stories: We’ll dig into a couple of those below. Of the requests that do reach llms.txt files, named AI bots account for 19.5%. While AI bots are the largest identifiable readership of llms.txt, the breakdown by AI bot type shows the file isn’t serving the AI tools most people have in mind. We group them four ways: Here’s how they size up… *statespace-indexer: operator identified as Statespace (agentic infrastructure), IP ranges unconfirmed. Sidenote. Quick reminder: This analysis covers the 3% of files that received any requests at all, not to the total 137K domains. That equates to roughly 1.1K domains and 22K requests in total—so we’re still only studying a tiny pool. Also, “fetched” doesn’t mean “read”. Many bots may have fetched the llms.txt file without ever acting on what’s inside. Every figure in this study is therefore a ceiling on actual llms.txt consumption. For instance, 19.5% of requests from AI is the most generous possible reading. Actual AI consumption is somewhere at or below this. AI agents, and the infrastructure built to serve them, drive 10.5% of llms.txt requests—more than any other type of AI bot. This finding lines up with a hunch that many in the industry already had. We heard earlier from John Mueller that llms.txt works best as reference material for AI coding agents. Chris Long, Founder of Nectiv, has also stated that, even if llms.txt doesn’t help you in Google search, the file has utility if your customers “are using Claude Code to source recommendations” Our Bot Analytics data supports both ideas. We see llms.txt files being fetched far less by the search and AI bots that are seemingly responsible for visibility, and far more by the agentic tools that seek out structured information and/or act on a user’s behalf. *statespace-indexer: operator identified as Statespace (agentic infrastructure), IP ranges unconfirmed. Aside from statespace-indexer and GPTBot, Claude-Code (Anthropic’s coding agent), out-fetched every AI retrieval bot, every AI assistant, and every AI training crawler. Llms.txt files feed training corpora more than they feed AI search retrieval. In fact, AI training crawlers fetch llms.txt nearly 5X more than AI retrieval bots. So if llms.txt were to in any way impact your brand’s AI visibility, it would likely be upstream—not at the point of retrieval. Of all training crawlers, GPTBot is far and away the biggest fetcher of llms.txt. You won’t find a Gemini crawler in this list, because it doesn’t exist. Google trains and grounds Gemini on content fetched by regular Googlebot, and Google-Extended, the opt-out publishers use, is a robots.txt token rather than a crawler with its own user agent. Googlebot did fetch llms.txt files ~900 times in May, but Googlebot routinely fetches any URL it discovers on a site as part of normal search indexing, so those fetches don’t indicate special interest in llms.txt—it’s crawling the file the same way it crawls a sitemap or any other page. Whether any of that content then feeds Gemini is invisible to us. According to our data, AI retrieval bots account for just 1.1% of AI bot requests. Even when taken together with AI assistants and AI training crawlers, these bots still count for only 8.9% of requests (1.6% less than AI agents). OAI-SearchBot, PerplexityBot, and Claude’s search crawler combined made only a couple of hundred fetches across thousands of sites. If you are planning on generating an llms.txt in hopes of boosting your AI citations, you may want to think again. A whole ecosystem has formed around auditing, scoring, validating, and studying the llms.txt standard, before we’ve even established whether any major AI platform actually reads it. Three categories account for 12% of all requests combined. Commercial tools scan websites and score their readiness for AI search and agent discovery, with llms.txt presence as one of many signals. The most active, CairrotReadinessBot, belongs to Cairrot, a WordPress-focused AEO platform launched in late 2025. Then you have the mainstream website builders like Framer, Lovable, and Wix all baking AI-readiness checks into their products. Lms.txt adoption has become a platform default before it’s even become a webmaster decision. There’s an ecosystem of tools that catalog the llms.txt files that almost nobody else reads. Dedicated scanners, validators, and directories built solely for llms.txt files send more requests than AI retrieval bots and AI assistants. The largest single research crawler in the dataset identifies itself as prompt-injection-survey/1.0. Someone is systematically studying llms.txt as a prompt injection opportunity that AI agents are designed to ingest and trust. The security implications of agents trusting llms.txt files at scale have barely been discussed, and yet potential bad actors are already on the case. AI tools never go looking for llms.txt files that aren’t there, so publishing one does not put you on any AI radar. We analyzed every request to /llms.txt paths that returned a 404 and found the cleanest split we’ve seen in bot data: where on the one hand valid files drew 96% bot traffic, missing files drew 98% human traffic, and the AI bot share of those 404s was zero. The people probing for absent llms.txt files are humans typing the URL into a browser, presumably SEOs checking on competitors. This kills the assumption that AI systems actively hunt for llms.txt files, and that a site without one is missing a knock at the door. AI tools fetch llms.txt when a link, an index, or a user instruction tells them it exists. How to check your own llms.txt bot traffic If you want to see which bots are actually hitting your llms.txt file, head to Ahrefs Bot Analytics and add a filter for Page URL → Contains → llms.txt, then hit Apply. This narrows everything down to requests hitting your llms.txt file (or any pages with “llms.txt” in the URL, like blog posts about it). We don’t have an llms.txt file on the Ahrefs site but we are getting some bots hitting that page, as indicated by the 404 status. From there, you can check: You can also use the AI bots filter at top of the page to strip out other crawlers and see only the LLM-related ones. And, remember, a bot requesting your llms.txt isn’t proof anything read or acted on it. It only tells you the file was fetched. If your goal is showing up in ChatGPT, Perplexity, or AI Overviews, an llms.txt file is largely decoration. AI search bots barely fetch them, no AI system goes looking for them, and 97% of existing files attract no readers of any kind. And remember that requests are the generous measure. Whether bots act on what they fetch is another question Here are the pros and cons, side-by-side. My verdict: the cons outweigh the pros right now. If you want to show up in AI search, there are more reliable ways to improve your visibility than this file. But if you’re still toying with the idea of generating llms.txt, here are the steps you should take: This study answers how many sites publish llms.txt, and who reads it. But there are a couple of other questions worthy of further research that were beyond the scope of this study: Mueller called llms.txt a temporary crutch. But that crutch seems to already have its own supply chain: platforms generating llms.txt files, an industry auditing them, and security researchers studying them, all before the “readers” actually showed up. Either we’re watching the early scaffolding of a real standard, or we’re watching the SEO industry prove it can productize anything. Our money is on a bit of both.
CATEGORYTYPEREQUESTS% OF TOTAL SEO audit toolsCrawl sites for traditional SEO health checks, with no specific interest in llms.txte.g. SiteAuditBot, WebPageTest Auditing 4,776 21.7% Other and unidentifiedAnonymous SDK defaults and bots whose purpose or operator we could not determinee.g. node, satoric-indexer Unknown 3,278 14.9% General web crawlersIndex the web for search and product discovery, with no stated AI-agent use casee.g. Googlebot, Amazonbot Crawling 2,871 13.1% Tech profiling toolsCrawl sites to identify technology stacks and business intelligence datae.g. BuiltWith, Dataprovider Profiling 2,546 11.6% AI agents & agentic infrastructureAI agents acting on a user’s behalf, plus the crawlers and tooling built to serve theme.g. Claude-Code, IbouBot AI 2,302 10.5% GEO/AEO toolsScan websites and score their readiness for AI search and agent discoverye.g. CairrotReadinessBot, AuditMetricBot Studying llms.txt 1,278 5.8% AI training crawlersCollect data for model buildinge.g. GPTBot, ClaudeBot AI 1,179 5.3% llms.txt discoverability botsSpecifically scan, validate, or catalogue llms.txt filese.g. LLMS-Txt-Scanner, txtfeed-bot Studying llms.txt 793 3.6% Service and social botsFetch URLs to generate link previews in messaging apps and social platformse.g. Slackbot, Skype URI Preview Social 645 2.9% Research botsCrawl for academic or investigative purposes, including security researche.g. prompt-injection-survey, ResearchProject Studying llms.txt 585 2.7% AI assistantsBrowse the web on behalf of a user in response to a single querye.g. ChatGPT-User, Claude-User AI 559 2.5% AI retrieval botsFetch pages to answer live user queries in AI search productse.g. OAI-SearchBot, PerplexityBot AI 233 1.1% 
The agentic web is the real consumer, sending 10.5% of requests
Training crawlers are the second-largest AI category at 5.3%
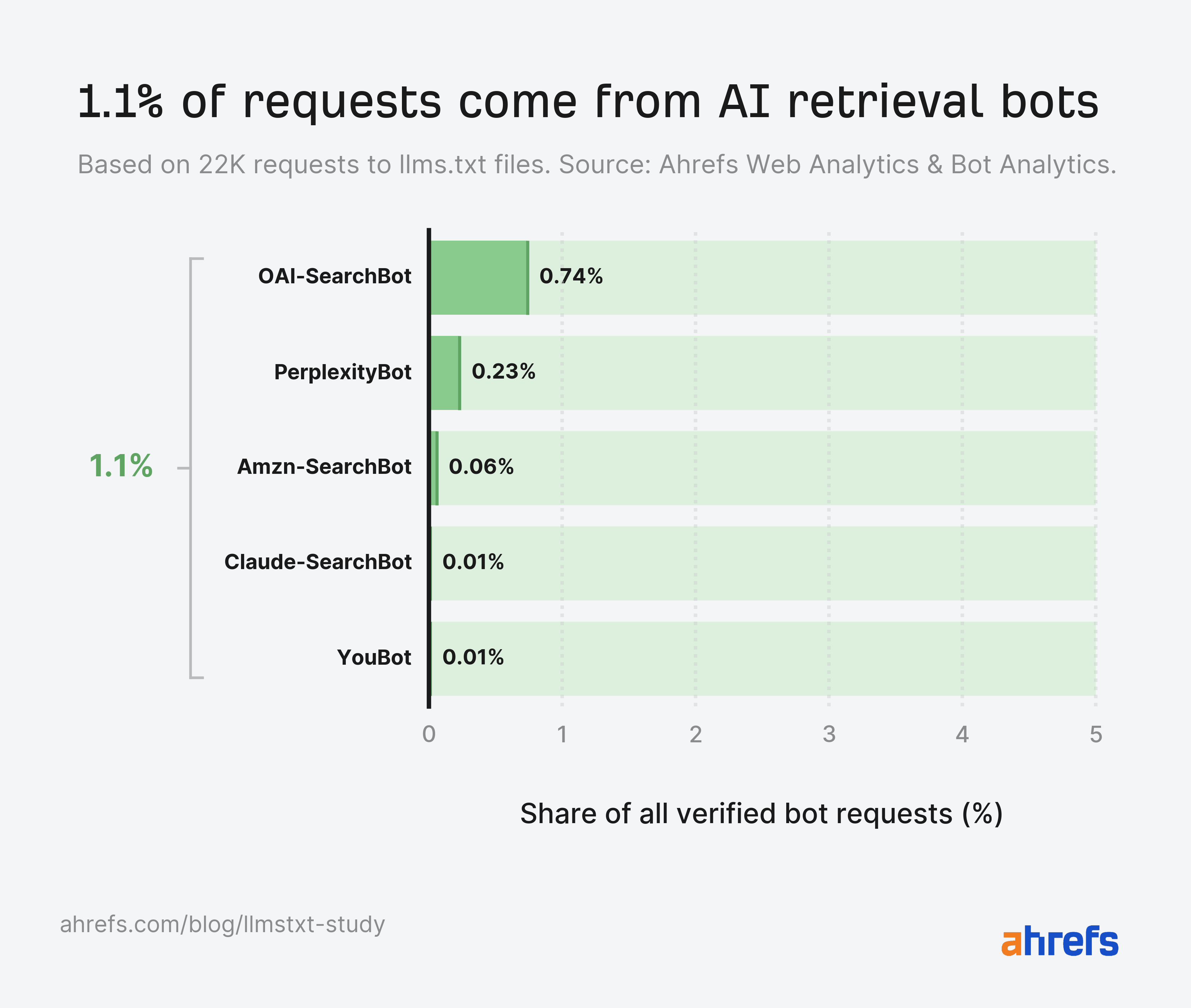
AI retrieval bots barely register, with 1.1% of total requests
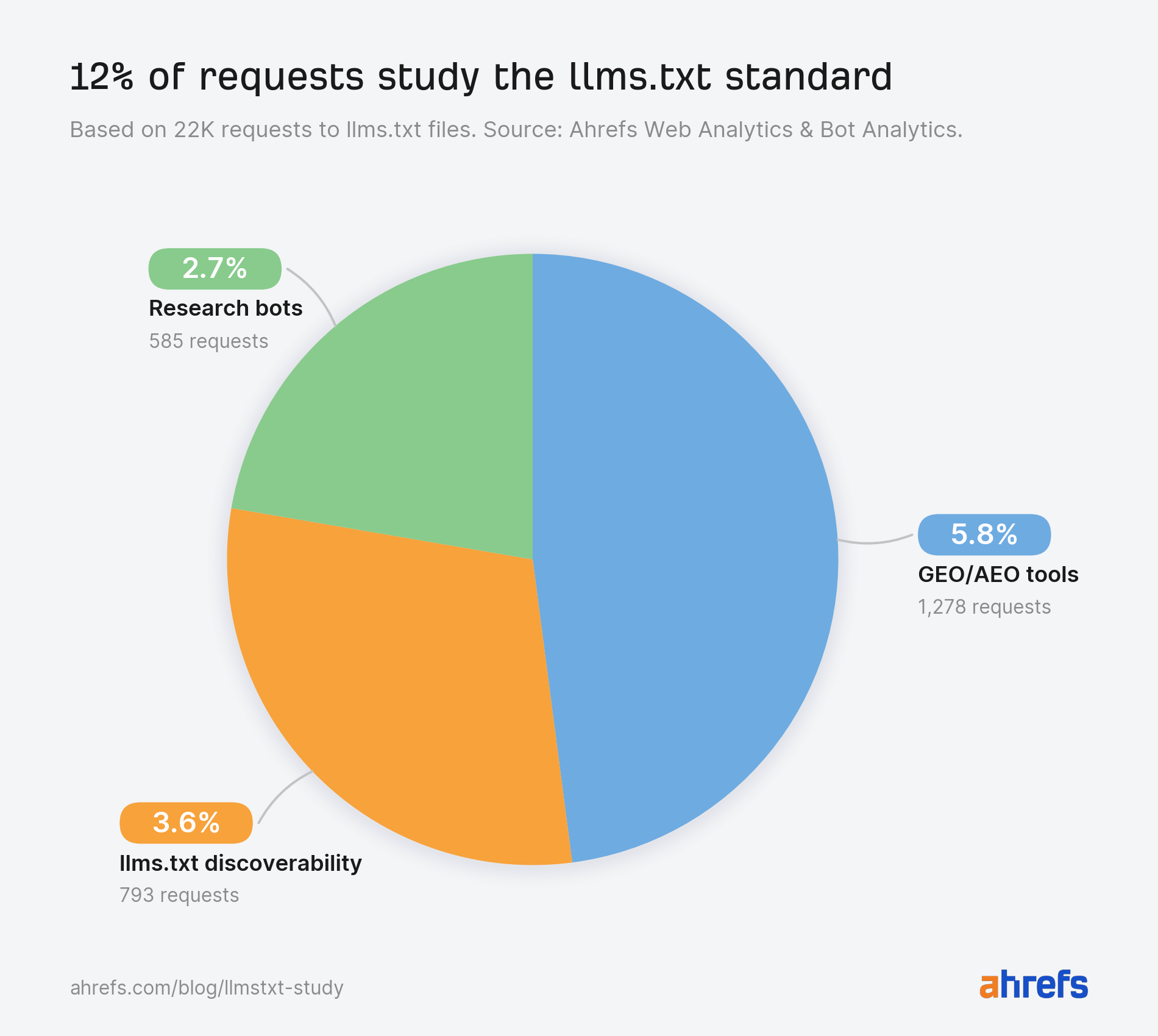
GEO/AEO tools send 5.8% of requests
llms.txt discoverability bots cover 3.6% of requests
Research bots send 2.7% of requests
PROSCONS Publishing llms.txt is cheap, and platforms like Wix will increasingly do it for you. The base rate is brutal: 97% of existing llms.txt files attract no readers of any kind. The closest thing to an intended audience in our data is coding agents. If your customers use coding agents, or if agents act on your site, the file stands a real chance of being read. It won’t help your AI search visibility today. AI retrieval bots barely fetch these files, and no AI system goes looking for one you haven’t published. It may futureproof your strategy. Google has made it clear that the future of search is agentic. If agents end up mediating AI search, rather than retrieval bots fetching pages directly, llms.txt could start influencing AI visibility through the agent layer. Publishing is only half the job. Agents fetch llms.txt when directed, not speculatively, so an unlinked file is unlikely to get picked up. It’s a security risk. Agents are built to trust this file, and potential bad actors are already probing llms.txt for prompt injection. A stale or compromised file misleads every agent that reads it.













![Q2 SEO & AI Update: How To Track & Optimize AI Search Performance [Webinar] via @sejournal, @hethr_campbell](https://www.searchenginejournal.com/wp-content/uploads/2025/03/featured-9-84.png)



















